Automation makes running tests faster and more frequently than manual testing a breeze. Tons of tools and frameworks exist to automate every kind of test you can imagine. But automation isn't free. It takes real software development chops to build and maintain. This post tackles test automation maintenance head-on, giving you practical strategies to keep your automated tests running smoothly so you can focus on shipping high-quality software.
Ongoing maintenance costs are inevitable. Products evolve. Features change. Better tools come out. And things don’t always turn out right the first time. Teams can feel trapped if the burden of their test projects becomes too great.
So, when is test automation maintenance too much? At what point does it take too much time away from actually testing product behaviors and finding bugs? Let’s look at three ways to answer this question.
Calculating the True Cost of Test Automation
One way to determine if automation maintenance is too burdensome is through the “hard math.” This is the path for those who like metrics and measurements. All things equal, the calculations come down to time.
Assume an automated test case is already written. Now, suppose that this automated test stops working for whatever reason. The team must make a choice: either fix the test or abandon it. If abandoned, the team must run the test manually to maintain the same level of coverage. Both choices – to fix it or to run it manually – take time.
Clearly, if the fix takes too much time to implement, then the team should just run it manually. However, “too much time” is not merely a comparison of the time to fix versus the time to run manually. The frequency of test execution matters. If the test must be run very frequently, then the team can invest more time for the fix. Otherwise, if the test runs rarely, then the fix might not be worthwhile, especially if it takes lots of time to make.
Let’s break down the math. Ultimately, to justify automation:
Time spent on automation < Time spent manually running the test
Factoring in fixes and test execution frequency:
Time to fix + (Automated execution time x Frequency) < (Manual execution time x Frequency)
Isolating the time spent on the fix:
Time to fix < (Manual execution time – Automated execution time) x Frequency
There’s a famous xkcd comic entitled “Is It Worth the Time?” that illustrates this tradeoff perfectly.
Let’s walk through an example with this chart. Suppose the test in question runs daily, and suppose that the automated version test runs 1 minute faster than the manually-executed version. Over 5 years, this test will run 1825 times. If the test is automated, the team will save 1825 minutes in total, which is a little more than 1 day. Thus, if the team can fix the test in less than a day, then fixing the test is worth it.
In theory, the hard math seems great: just pop in the numbers, and the answer becomes obvious. In practice, however, it’s rather flawed. The inputs are based on estimations. Manual test execution time depends on the tester, and automated execution time depends on the system. Test frequency can change over time, such as moving a test from a continuous suite to a nightly one. Frequency also depends on the total lifespan of the test, which is difficult to predict. From my experience, most tests have a longevity of only a few years, but I’ve also seen tests keep going for a decade.
Furthermore, this calculation considers only the cost of time. It does not consider the cost of money. Automated testing typically costs more money than manual testing for labor and for computing resources. For example, if automation is twice the price, then perhaps the team could hire two manual testers instead of one automation engineer. The two testers could grind through manual testing in half the time, which would alter the aforementioned calculations.
Overall, the hard math is helpful but not perfect. Use it for estimations.
Key Takeaways
- Assess the True Cost of Automation: Regularly compare the time spent maintaining automated tests versus running them manually. Factor in execution frequency and long-term costs to make informed decisions about which tests to automate and maintain.
- Look for Systemic Problems: Constantly fixing broken tests can indicate deeper issues like unstable environments, flaky scripts, or poor test design. Addressing these root causes is more effective than endless patching.
- Prioritize Your Testing Efforts: Don't let test maintenance overshadow other essential testing activities. Consider the opportunity cost – could your team's time be better spent on exploratory testing, writing new tests, or other valuable tasks? Explore services like MuukTest to streamline your automation and free up your team.
When Test Automation Feels Wrong
Another way to determine if automation maintenance is too burdensome is through the “gut check.” Teams intuitively know when they are spending too much time fixing broken scripts. It’s an unpleasant chore. Folks naturally begin questioning if the effort is worthwhile.
My gut check triggers when I find underlying issues in a test project that affect multiple tests, if not the whole suite. These issues run deeper than increasing a timeout value or rewriting a troublesome assertion. A quick fix may get tests running again temporarily, but inevitably, more tests will break in the future. Since underlying problems are systemic in nature, they can require a lot of effort to fix properly. I size up the cost as best as I can and do a little hard math to determine if the real fixes are worthwhile.
Here are six underlying issues that always trigger my gut check:
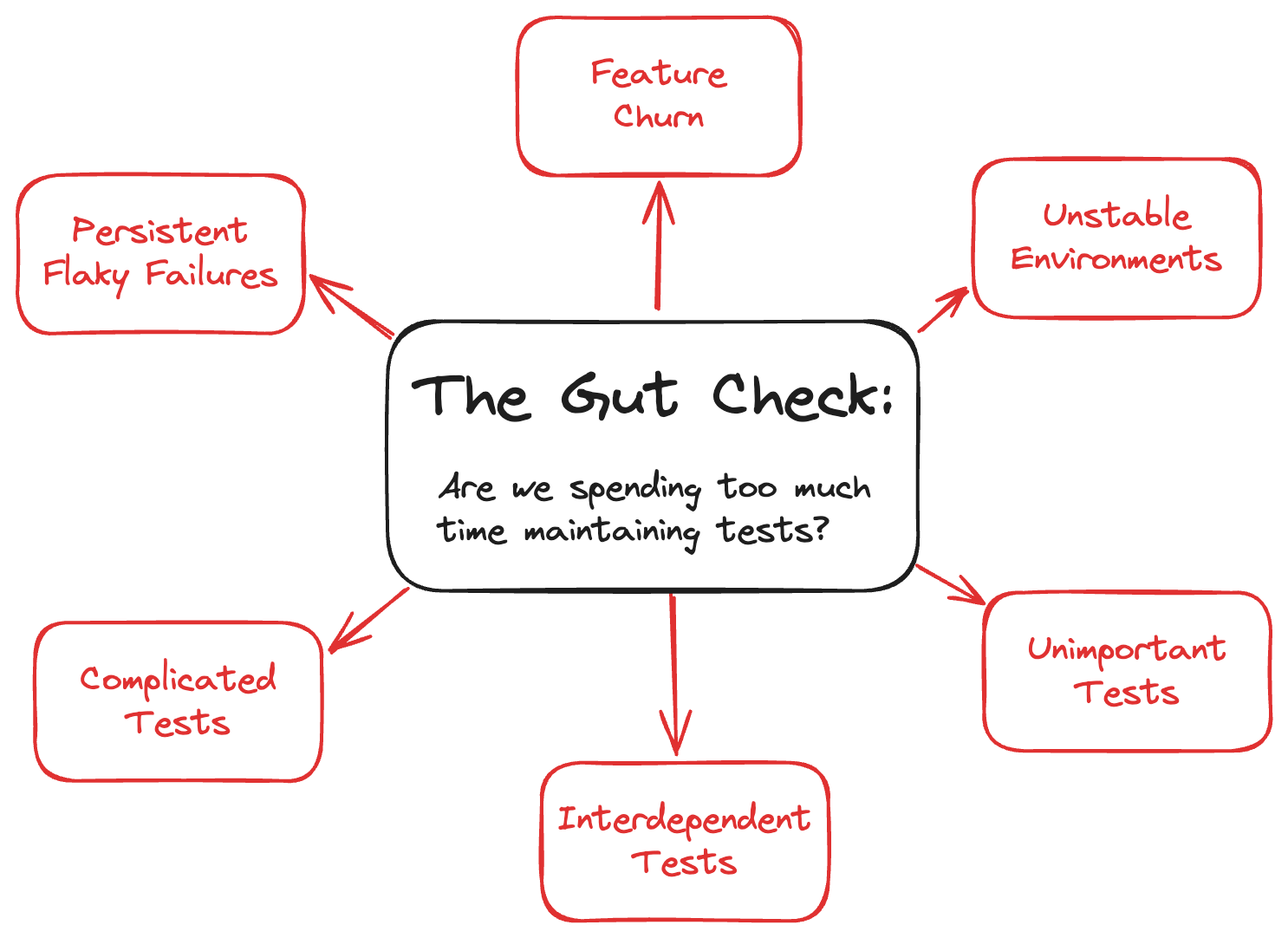
Why Do Features Keep Breaking My Tests?
Development is dynamic. The product under test is always changing. Sometimes, a team makes changes iteratively by adding new behaviors upon the existing system. Other times, a team decides to rewrite the whole thing, changing everything. (Hey, they need to try that newfangled frontend framework somehow!)
Changes to the product inevitably require changes to the tests. This is normal and expected, and teams should expect this kind of maintenance cost. Excessive changes, however, become problematic. If features keep churning, then the team should consider running tests manually until the product becomes more stable.
Triggers for Maintenance Testing
Maintenance testing keeps software tests up-to-date as the software itself changes. This is crucial because software constantly evolves. So, what events typically trigger the need for maintenance testing? Several common scenarios come up, often related to the dynamic nature of software development. For example, adding new features is a frequent trigger. Every new feature needs tests to ensure it works correctly and doesn't break existing functionality. Bug fixes also trigger maintenance testing. After developers fix a bug, testers need to verify the fix and ensure it hasn't introduced new problems. Sometimes, the fix itself requires changes to existing tests.
Even seemingly unrelated updates, like updating the operating system or migrating to a new platform, can trigger the need for maintenance testing. These changes can impact how the software behaves and therefore require adjustments to the tests. Sometimes, the need for maintenance testing arises from issues within the test suite itself. Test scripts can become brittle or outdated, requiring updates to keep them aligned with the evolving software. As I mentioned earlier, underlying problems in a test project, like flaky tests or poor test design, can necessitate significant maintenance efforts. These issues often signal a need to refactor or even rewrite parts of the test suite.
It's important to address these underlying problems to prevent ongoing maintenance headaches and ensure the long-term effectiveness of your automated tests. If your team is constantly firefighting brittle tests, it might be time to step back and evaluate the overall health of your test automation framework. Consider investing in improving the framework's robustness and maintainability to reduce future maintenance burdens. Sometimes, a little proactive maintenance can save a lot of reactive scrambling later on. We specialize in AI-powered test automation that can help streamline your testing processes and reduce maintenance overhead.
Are Your Test Environments Stable Enough?
An “unstable” environment is one in which the product under test cannot run reliably. The app itself may become cripplingly slow. Its services may intermittently go down. The configuration or the data may unexpectedly change. I once faced this issue at a large company that required us to do all our testing in a “staging” environment shared by dozens of teams.
Unstable environments can ruin a test suite that is otherwise perfectly fine. Humans can overcome problems with instability when running their tests, but automated scripts cannot. Teams should strive to eliminate instability in test environments as a prerequisite for all testing, but if that isn’t possible, then they should build safety checks into automation or consider scaling back their automation efforts.
Testing What Truly Matters
Let’s face it: some tests just aren’t as valuable as others. In a perfect world, teams would achieve 100% coverage. In the real world, teams need to prioritize the tests they automate. If an unimportant test breaks, a team should not just consider if the test is worth fixing: they should consider if the test is worth keeping.
When considering if a test is important, ask this question: If this test fails, will anyone care? Will developers stop what they are doing and pivot to fixing the bug? If the answer is “no,” then perhaps the test is not important.
Untangling Interdependent Tests
Automated test cases should be completely independent of each other. They should be able to run individually, in parallel, or in any order. Unfortunately, not all teams build their tests this way. Some teams build interdependencies between their tests. For example, test A might set up some data that test B requires.
Interdependencies between tests create a mess. Attempting to change one test could inadvertently affect other tests. That’s why test case independence is vital for any scalable test suite.
Simplifying Your Automated Tests
Simple is better than complex. A test case should be plainly understandable to any normal person. When I need to read a complicated test that has dozens of steps and checks a myriad of behaviors, I feel quite overwhelmed. It takes more time to understand the intentions of the test. The automation code should also follow standard patterns and conventions.
Simple tests are easy to maintain. Complicated tests are harder. ‘Nuff said.
Specific Techniques for Maintaining Tests
So, how can teams keep the maintenance burden low? There are specific techniques that can help. Maintenance testing, as a whole, keeps tests up-to-date with the software. This includes confirmation testing (checking new code) and regression testing (making sure existing features still work). Think of it like regularly cleaning your house—little by little, so it doesn’t become overwhelming.
Here are some key techniques:
- Modularize for Reusability: Create reusable modules for common test steps. Instead of rewriting the login steps for every single test, write them once and reuse them everywhere. This way, if the login process changes, you only need to update the module in one place. This also simplifies test creation—like assembling pre-fabricated components in a house.
- Page Object Model (POM): POM is a design pattern that creates an object repository for web UI elements. This keeps your test code cleaner and easier to update when the UI changes. It’s like having a blueprint of your house—if you remodel, you update the blueprint, and everyone knows where things are. This is especially useful for applications with complex user interfaces.
- Centralized Test Data: Store your test data (like usernames, passwords, product details) in a central location, like a spreadsheet or database. This makes it easier to manage and update test data without digging through individual test scripts. Think of it as a pantry for your tests—all the ingredients are in one place. This also helps with data consistency across tests.
- Version Control: Use a version control system like Git to track changes to your test scripts. This allows you to easily revert to previous versions if something goes wrong, and it helps with collaboration among team members. It’s like having a history book for your tests—you can see who did what and when. This is essential for team projects and for tracking the evolution of your tests.
- Regular Reviews: Regularly review your test scripts to ensure they are still relevant and efficient. Remove redundant tests, update outdated ones, and look for opportunities to improve. Think of it as decluttering your tests—get rid of what you don’t need anymore. This helps keep your test suite lean and focused.
- Automated Tools: Leverage automated tools that can help with test maintenance. Some tools can automatically detect when tests break due to code changes and even suggest fixes. AI-powered tools can also help automate test updates and identify insignificant changes, reducing manual effort. These tools are like having a robot helper for your tests—they take care of the tedious tasks. Prioritize automating the most critical parts of your software to maximize impact.
Addressing the challenges of test maintenance head-on—like cost, false positives, and communication issues—is key. By using these techniques, teams can streamline their test maintenance, reduce costs, and improve the overall quality of their software.
Conquering Flaky Tests
Flakiness is the bane of black-box test automation. It results from improperly-handled race conditions between the automation process and the system under test. Automation must wait for the system to be ready before interacting with it. If the automation tries to, say, click on a button before a page loads it, then the script will crash and the test will fail.
A robust test project should handle waiting automatically at the framework level. Expecting testers to add explicit waits to every interaction is untenable. Tests that don’t perform any waiting are flatly unmaintainable because they could intermittently fail at any time.
Challenges of Maintaining Tests
Test automation maintenance can be a significant challenge. It's more than just fixing broken tests; it's about managing the overall health and effectiveness of your test suite. One of the biggest hurdles is the ongoing cost of maintenance. As products evolve and features change, tests need to adapt. This constant evolution requires dedicated time and resources, which can strain teams.
Another common issue is the impact of frequent product changes. Rapid iterations can lead to a constant cycle of updating and fixing tests, diverting valuable time away from developing new features. If features are constantly in flux, it might be more efficient to rely on manual testing until the product stabilizes.
Unstable environments also present a major obstacle. If your testing environment isn't reliable, your automated tests won't be either. This can lead to flaky tests and inaccurate results, making it difficult to trust your automated suite. Investing in a stable testing environment is crucial for successful test automation.
Flaky tests are a constant source of frustration. These tests pass or fail intermittently without any code changes, making it difficult to pinpoint the root cause of issues. Addressing flakiness often requires significant debugging effort and can erode confidence in the entire test suite. A robust framework that handles waiting automatically can help mitigate this.
Finally, the time investment required for test maintenance can be overwhelming. Teams using open-source tools can spend a significant portion of their week just maintaining tests. This can pull developers away from more strategic work and slow down releases. Finding ways to streamline maintenance and reduce the time investment is essential.
Is Test Automation Maintenance Worth It?
A third way to determine if automation maintenance is too burdensome is its opportunity cost. What could a team do with its time instead of fixing broken scripts? The “hard math” from before presented a dichotomy between manual execution and automation. However, those aren’t the only two factors to consider.
For example, suppose a team spends all their testing time running existing automated suites, triaging the results, and fixing any problems that arise. There would be no capacity left for exploratory testing – and that’s a major risk. Exploratory testing forces real humans to actually try using the product, revealing user experience issues that automation cannot catch. There would also be no time for automating new tests, which might be more important than updating old, legacy tests.
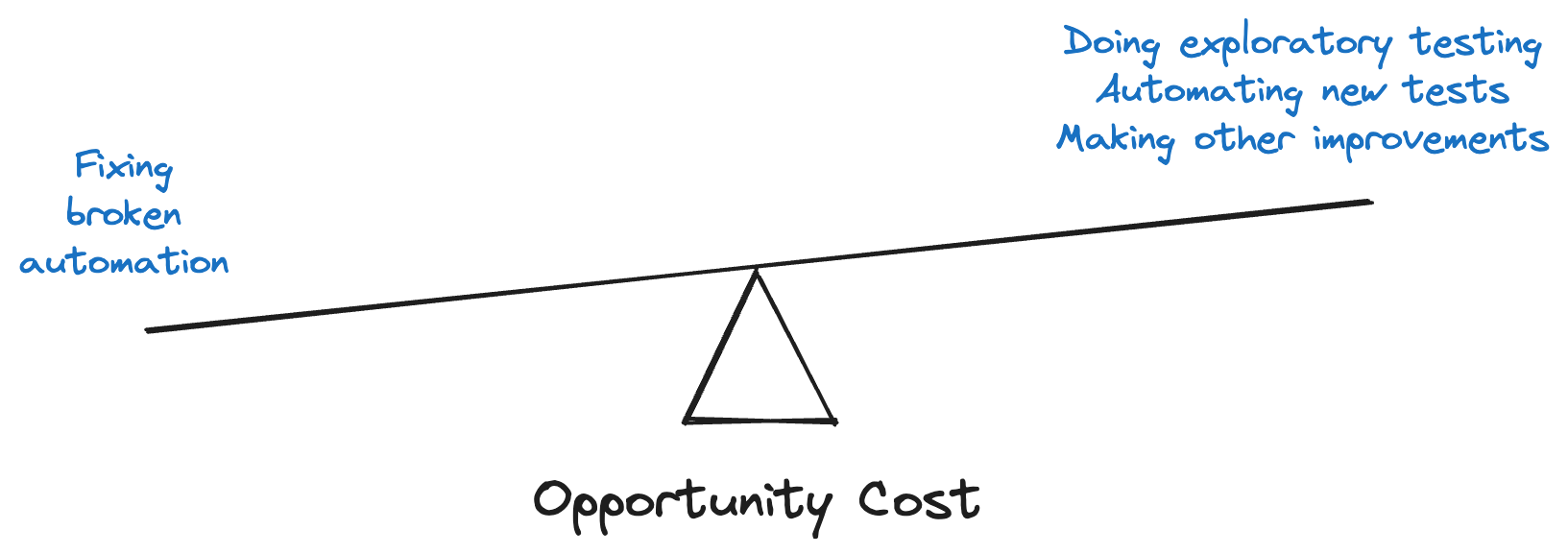
Even if a team’s gut check leans toward fixing broken automation, and even if the hard math validates that intuition, a team may still choose to abandon those tests in favor of other, more valuable activities. It’s a tough call to make. Justify it with opportunity cost.
Statistics on Maintenance Burden
Unfortunately, struggling with test automation maintenance is common. A 2023 study found that 55% of teams using open-source tools like Selenium, Cypress, and Playwright spend at least 20 hours a week on test maintenance. That’s half the work week! This significant time commitment pulls developers away from building new features and can slow down product releases. When weighing the benefits of automation, factor in this potential overhead. It's a real cost that can impact your team's velocity.
Consider also the hidden costs of maintenance. If a team is constantly firefighting flaky tests or reworking scripts due to code changes, their morale and productivity can suffer. This can lead to burnout and decreased job satisfaction, impacting the overall team dynamic and potentially leading to higher turnover. Investing in a robust test automation strategy from the start can mitigate these risks and create a more sustainable development process. It’s important to acknowledge the human cost of excessive maintenance and strive for a balanced approach to test automation.
The Long-Term Benefits of Effective Maintenance
While the costs of maintaining test automation can feel overwhelming, the long-term benefits are significant. Maintenance testing saves time and money. Instead of creating entirely new tests every time the software changes, teams can simply update the existing ones. This keeps tests accurate and reliable, leading to better software quality and faster release cycles. Think of it as tending a garden: regular weeding and pruning keeps it healthy and productive in the long run. A proactive approach to maintenance ensures your tests remain a valuable asset, rather than a burden.
Effective maintenance also ensures your automated tests remain a valuable asset. Regularly updating tests ensures they're still relevant and effective at finding bugs. Maintenance helps automated tests stay up-to-date with code changes, making testing more efficient and preventing regressions. This, in turn, builds confidence in the software and allows teams to focus on delivering value to users, rather than constantly fixing broken tests. Many companies have found that prioritizing test maintenance leads to a more stable and predictable development process. A well-maintained test suite is a safety net, allowing teams to move faster and with more confidence.
Making Test Automation Maintenance Work for You
Whichever way you determine if test maintenance is taking too much time away from finding defects, be sure to avoid one major pitfall: the sunk cost fallacy. Endlessly fixing broken scripts that keep flailing and failing is counterproductive. Test automation should be a force multiplier. If it becomes a force divider, then we’re doing it wrong. We should stop and reconsider our return on investment. Use these three ways – the hard math, the gut check, and the opportunity cost – to avoid the sunk cost fallacy.
Types of Maintenance Testing
Maintenance testing keeps software tests up-to-date as the software itself changes. Think of it like updating a game's instructions after a new release—you need to make sure everything still works as expected. There are two main types: confirmation testing, which verifies new features work correctly, and regression testing, which ensures existing features still work after changes.
Best Practices for Minimizing Maintenance
Effective maintenance testing involves more than just fixing broken tests; it requires a proactive approach to minimize future issues. Regularly reviewing and refining your tests is key. Choosing the right tools is also crucial. A user-friendly no-code/low-code test automation platform simplifies updates. Finally, automated test reporting offers insights into what's working and what's not, enabling prompt issue resolution.
Proactive Monitoring
Ignoring test maintenance leads to future costs. HeadSpin highlights the importance of proactive monitoring and using robust tools to streamline test automation. Catching potential problems early prevents them from becoming larger, more complex issues.
Leveraging AI/ML
AI-powered tools are changing test maintenance. These tools can automatically update tests and identify insignificant changes, reducing manual effort. This frees up your team for more strategic testing activities.
Outsourcing Maintenance
If in-house test automation maintenance is too much, consider outsourcing. Outsourcing maintenance to a specialized team frees up internal resources and ensures tests stay current. This lets your team focus on product development and other key tasks.

Frequently Asked Questions
How do I know if I'm spending too much time on test automation maintenance?
Consider a few factors. First, track the time it takes to fix a broken automated test versus running it manually, keeping in mind how often you run that test. More frequent tests justify more maintenance time. Second, trust your gut. If maintaining your tests feels like a constant struggle, it probably is. Lastly, think about what else your team could be doing. Could that maintenance time be better spent on exploratory testing or building new automation?
What are some common problems that make test automation maintenance difficult?
Frequently changing features, unstable test environments, overly complex tests, interdependent test cases, and flaky tests are common culprits. These underlying issues can make maintenance a real headache and significantly increase the time and effort required. Addressing these problems proactively can save you a lot of pain down the road.
What are some practical tips for reducing test automation maintenance?
Build modular, reusable test components. Use a page object model (POM) for web UI testing. Centralize your test data. Use version control for your test scripts. Regularly review and refine your tests, removing redundant or outdated ones. And consider using tools that can help automate some of the maintenance tasks.
What is the “sunk cost fallacy” in test automation, and how can I avoid it?
The sunk cost fallacy is the trap of continuing to invest in something (like fixing broken tests) simply because you've already invested so much, even when it's no longer beneficial. To avoid it, regularly evaluate the return on investment of your test automation efforts. Be willing to abandon tests that are no longer providing value.
What if my team doesn't have the bandwidth to handle test automation maintenance effectively?
If maintaining your test automation in-house is becoming too much of a burden, consider outsourcing it to a specialized team. This frees up your internal resources to focus on other critical tasks, like developing new features and performing exploratory testing, while ensuring your tests remain up-to-date and effective. You can also explore AI-powered test automation solutions that often require less maintenance.