- AI testing tools excel at the easy 80% but consistently miss the high-risk 20%. They automate predictable flows well, but struggle with dynamic data, branching logic, async behavior, integrations, and real-world edge cases, where most critical bugs actually hide.
- The hard 20% of testing requires human judgment, not just automation. AI can generate steps, but it can’t understand intent, risk, business rules, user roles, or the messy variability of real usage. High-impact test cases still need human-designed coverage.
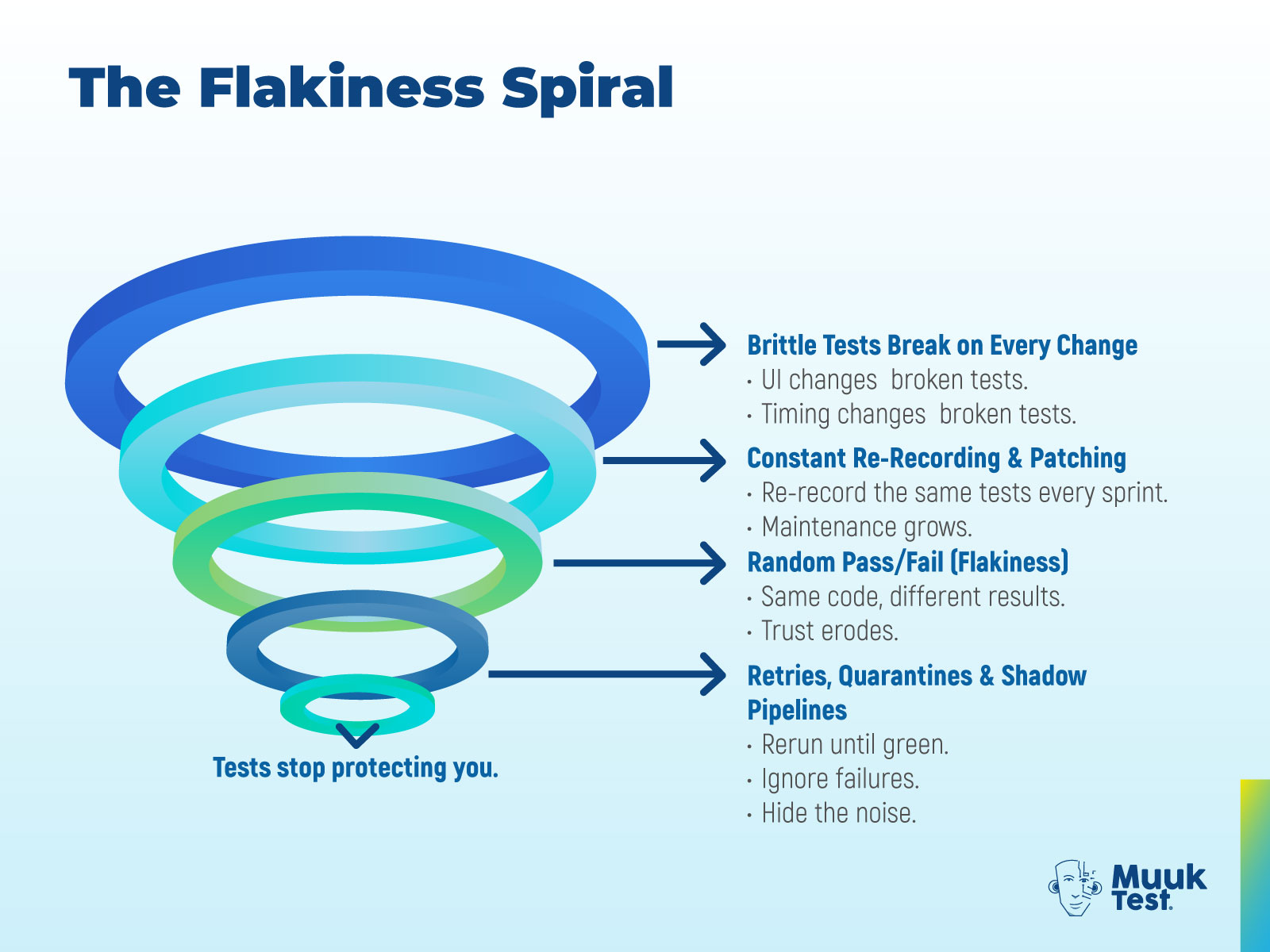
- Forcing AI tools into complex scenarios triggers a flakiness spiral. Teams fall into endless re-recordings, retries, quarantines, and brittle tests that break constantly, eroding engineer trust and letting real regressions slip through.
- Real QA maturity comes from strategy, not tool volume. AI can accelerate throughput, but only a hybrid approach: AI + human insight, delivers true reliability. Without that strategy, automation becomes noise instead of protection.
This post is part 2 of a 4-part series on The Real ROI of AI Testing Tools - From Illusion to Impact:
- Why DIY AI Testing Tools Only Cover the Easy 80%
- Why DIY AI Testing Tools on their own Struggle with the Hard 20% ← You're here
- How CTOs Can Maximize ROI from AI Testing Tools - Dec 9, 2025
- MuukTest’s Hybrid QA Model: AI Agents + Expert Oversight - Dec 16, 2025

If you’re starting to feel the cracks in your AI-generated tests - a customer churn here, an unexpected regression there, or an entire team quietly losing trust in a dashboard full of green checks- you’re not alone.
Many engineering leaders discover the same reality after the first few sprints: the AI tool isn’t the problem, but its limits are. The easy tests run smoothly, but the brittle ones demand constant maintenance. The flaky ones slow your pipeline. And the “all green” results stop feeling like something you can bet a release on.
And if you’re seeing this pattern, you’re not alone. The pain always shows up first in the hard 20% of testing that AI tools consistently miss. Which is why we decided to write this article to break down the limitations of AI testing tools and help you avoid the same painful mistakes many tech teams struggle with.
What Makes the Hard 20% of Testing Hard
What do we mean by “the hard 20%” of testing? These are the test cases that aren’t straightforward. They’re the scenarios that manual QA engineers obsess over, but DIY AI tools often skip.
Key characteristics include:
- Complex data flows: Real users input messy, varied data. Shallow tests often use the same few “happy” data sets and miss edge cases (maximum lengths, special characters, unusual combinations) that can break functionality.
- Authentication and user states: Bugs often hide in state changes, like what happens when a user logs out and in again, or when an admin user (vs. a normal user) accesses a feature. Edge case automation for different roles, permissions, or sequences is usually absent in AI-generated tests, leaving gaps around security and state management.
- Conditional logic and branching paths: User journeys with lots of “if/else” conditions. Think of an app where an onboarding flow splits into different paths based on user type, or a settings page that reveals new options only for certain plans. These branching scenarios require understanding context and business rules, something AI-generated tests often don’t possess.
- Data-driven and dynamic behaviors: Features that behave differently depending on data or state. Dynamic UIs (such as a dashboard that changes based on user activity) or complex data flows (such as an algorithm that behaves differently with certain inputs) fall here. Hard 20% testing means handling variations that aren’t visible in a static UI screenshot; the stuff you only catch with deep domain knowledge.
- Interdependent workflows: Flows that span multiple features or systems. For example, a user action that kicks off a background job, updates a database, and sends an email. Each step might succeed on its own, but the workflow as a whole has weak points where things can go wrong. AI scripts that focus on one screen at a time miss these end-to-end chains.
- Multi-system integrations: High-risk tests often involve third-party services, APIs, or microservices in tandem. Payments, analytics, identity providers, when one system’s output becomes another’s input, simple record-and-playback tools falter.
- API + UI round trips: High-risk flows often involve a round trip – the UI makes an API call, something happens on the server, and the UI updates. A shallow test might only check the UI part (e.g., form submission yields a success message) without validating the backend result (was the transaction actually processed?). Many severe bugs (such as data not being saved or transactions not being committed) won’t be caught by a script that lacks end-to-end verification.
For instance, imagine a dashboard where admin-only features trigger external services. An AI tool that tests only default user paths will never hit that logic, meaning entire permission-based flows go untested.
These kinds of complex test automation scenarios require human insight to design appropriate test conditions. It’s hard by nature: interdependent, conditional, integrated, and data-driven. Exactly the kind of scenario DIY AI tools struggle with.
Why AI Tools Break Down in High-Risk Areas
If AI test tools are so advanced, why do they fail in these high-risk, complex areas? It comes down to the inherent limitations of AI testing tools when facing complexity:
- They don’t understand your system’s underlying logic: DIY AI test generators don’t truly understand your product. They see a series of clicks and UI elements, but they don’t know why a feature exists or what the underlying logic is supposed to do. They’ll happily assert that a checkbox appears, but they won’t know the checkbox enables a critical backend process. In complex paths, this lack of intent awareness means important assertions are never made.
- They misinterpret dynamic components: AI-driven tests often rely on visual cues or element locators. When the UI is dynamic (content loads asynchronously, elements move, or only appear after certain actions), the AI can get confused. We’ve seen AI tests click the wrong menu item or fail to wait for a crucial update, simply because the app didn’t match the recording exactly. The result is flaky tests or false positives that mask real issues.
- They struggle with timing and async flows: Many of the hard 20% of test cases involve race conditions or asynchronous events (such as waiting for an email or processing a queue in the background). AI tools aren’t great at handling unpredictable timing. They either time out too soon or pass “too easily” without actually verifying the async result. Subtle timing bugs, a classic source of production incidents, often slip by undetected.
- They treat complexity as noise, not as signal: The more complex and unconventional a scenario is, the more likely an AI script is to simplify or ignore it. Extra steps, edge conditions, unusual data; a human tester sees these as red flags to probe, but an automated tool often treats them as outliers to be normalized. In practice, an AI test might follow the simplest happy path and skip over variations, filtering out exactly the cases that need attention.
These types of bugs can turn fast into systemic issues. You can’t simply “tweak” an AI script to have good judgment or domain intuition. In high-risk software testing (the intricate scenarios that determine if your app stands or falls), it is common for AI tools to hit a wall of limitations. And when they do, things start to fall apart fast.
Why Flakiness Snowballs in AI-Generated Test Suites
Take a simple example: a multi-step onboarding flow with an email verification step. An AI tool can easily record the clean, linear version — fill out the form, click the link, and continue. But real users don’t always move in clean lines. Maybe the verification email is delayed by five seconds. Perhaps it arrives before the UI is fully ready. Maybe the user switches devices or tabs.
For humans, these are normal variations. For an AI-generated test, they’re chaos. One day, the test passes; the next day, it fails for reasons no one can reproduce. And instead of catching a regression, your team ends up fighting a test that’s simply out of its depth.
It starts with harmless inconsistencies, but quickly grows into a loop of instability: tests that break with minor UI changes, endless re-recordings, pipelines padded with retries, and a growing pile of quarantined failures the team no longer trusts.
As a result, confidence fades. Engineers stop believing failing tests reflect real issues. QA loses the leverage to hold the line on quality. And all the while, the hardest, riskiest parts of the product remain untested.
When using an AI tool, you can have thousands of tests running and still miss the critical regression that brings your system down. If your automation covers the easy 80%, it’s likely not covering the vital 20% where 80% of the bugs live. Or as our team puts it, most AI tools focus on the low-impact 80% of tests that deliver only ~20% of the value. The real value (real protection against nasty bugs) comes from the hard 20% of cases that only human-guided testing can design.
The Business Cost of Missing the Hard 20%
This gap doesn’t just create technical headaches; it quietly introduces organizational risk. Flakiness, shallow coverage, and misleading “all green” dashboards erode the pillars CTOs depend on: customer trust, engineering velocity, and the confidence to ship frequently without fear.
When the hard 20% isn’t tested, teams end up running in circles: spending more time debugging brittle scripts than delivering value, making decisions based on coverage metrics that don’t reflect actual risk, and firefighting production issues that should have been caught earlier. These blind spots are why AI-only automation hits a ceiling so quickly without human judgment shaping what gets tested and why tools generate volume, not safety.
And the impact becomes measurable fast. Low coverage in critical paths (authentication, checkout, API gateways) often hides latent bugs and silently slows your release cycle. Industry benchmarks recommend 70–80% coverage for core services and close to 100% coverage for authentication and payment logic, because failures in these areas cause the highest customer friction and the most costly regressions.
This is where a real QA strategy becomes mission-critical.
Why High-Impact Tests Need Human Insight
Industry leaders in the 2025 World Quality Report emphasize that AI augments but doesn’t replace traditional QA. A signal that today’s testing tools still hit a ceiling when product complexity rises. And that ceiling always appears in the hard 20%: the places where systems interact, logic branches, data changes shape, or timing becomes unpredictable.
This is where human judgment becomes essential. AI can generate steps, but it can’t understand risk, context, or intent. It can’t tell which path is business-critical, which scenario would cause customer churn, or which edge case represents a real-world workflow your users rely on. That kind of prioritization only comes from human experience.
Skilled QA engineers bring several advantages that AI alone cannot:
- Risk awareness: Experienced QA engineers think in terms of risk. They identify which parts of the system, if broken, would be catastrophic, and ensure those are tested thoroughly. AI treats all tests equally – humans know some tests are more important than others.
- Business logic understanding: Humans understand the “why” behind a feature. They know the real-world use cases and failure modes. This enables designing tests for edge behaviors that an AI, which only sees screens, would never consider.
- Adaptability and creativity: When an AI test fails, it often can’t tell if the app is wrong or the test is. A human can investigate: maybe the requirement changed, or the failure is revealing a new bug. Humans can adapt tests to new insights, whereas a tool will just rerun the same script, expecting different results.
- Oversight of AI output: AI can indeed accelerate testing by handling the easy 80%. But humans are needed to validate AI-generated tests, to tweak them for accuracy, and to extend them into that last 20%. In practice, the best results come from a hybrid approach – AI + human – not AI alone.
In short, AI test automation is powerful for scaling coverage, but it’s not a substitute for a real QA strategy. As we discussed in the previous article Why DIY AI Testing Tools Only Cover the Easy 80%, you can use AI to blast through the straightforward checks. Let the bots handle the mundane. But for the tricky stuff – the scenarios that keep you up at night – you still need a human in the loop. That’s how you bridge the gap between lots of tests and real confidence.
AI testing tools are incredibly effective at automating the easy, repeatable parts of your app and that’s a win worth celebrating. But speed and volume alone don’t equal safety. When coverage becomes shallow, brittle, or blindly trusted, you risk trading fast results for fragile quality.
The Path Forward for Reliable Testing
AI tools can automate the easy stuff at lightning speed, but only teams with strategy, context, and human insight can conquer the 20% that actually protects your product. That’s where the flakiness stops. That’s where risk gets managed. And that’s where quality becomes a competitive advantage instead of a constant fire drill.
And this brings us to the natural next question:
If AI tools can’t handle the hard 20% on their own… how do engineering leaders actually make them work?
That’s exactly what we’ll explore next. In our upcoming article: How CTOs Can Maximize ROI from AI Testing Tools, we’ll cover what strong QA leadership looks like in an AI-accelerated world and how to turn tools from something your team babysits into something that truly scales quality.
You won’t want to miss it.

Frequently Asked Questions
What makes the “hard 20%” of testing so difficult for AI automation tools?
The hard 20% includes scenarios involving dynamic data, branching logic, async workflows, user-specific states, multi-system integrations, and error handling. AI tools struggle here because these tests require interpreting intent, business rules, and system behavior, capabilities that AI-generated scripts don’t have.
Why do AI-generated tests become flaky in complex or high-risk scenarios?
Flakiness occurs because AI tools rely on static recordings and brittle locators. When UI state, timing, asynchronous events, or external services behave unpredictably, the test loses alignment with reality. Without human-designed stability checks or backend validation, these tests break easily.
How can engineering teams identify whether their AI test suite is missing the hard 20%?
Warning signs include: recurring regressions in production, a growing number of quarantined tests, constant re-recordings, passing tests that fail to verify backend behavior, and issues that only appear for specific user roles or data states. These indicate that the suite automates volume, not risk.
Can AI testing tools validate backend logic or multi-system integrations?
Most DIY AI tools cannot. They validate UI responses but usually don’t confirm database updates, microservice calls, asynchronous processes, or third-party integrations. End-to-end, cross-layer validation requires human-authored assertions and test design beyond UI recording.
How can teams improve coverage of the hard 20% without abandoning AI tools?
Use a hybrid strategy: let AI tools automate straightforward paths, while QA experts design tests for complex flows, integration behavior, error handling, and real-world edge cases. This reduces flakiness, strengthens risk coverage, and maximizes the value of AI-generated tests.